Dive Into Tendermint Consensus Protocol (I)
This article is written by the CoinEx Chain lab. CoinEx Chain is the world’s first public chain exclusively designed for DEX, and will also include a Smart Chain supporting smart contracts and a Privacy Chain protecting users’ privacy.
longcpp @ 20200618
This is Part 1 of the serialized articles aimed to explain the Tendermint consensus protocol in detail.
Part 1. Preliminary of the consensus protocol: security model and PBFT protocol
Part 2. Tendermint consensus protocol illustrated: two-phase voting protocol and the locking and unlocking mechanism
Part 3. Weighted round-robin proposer selection algorithm used in Tendermint project
Any consensus agreement that is ultimately reached is the General Agreement, that is, the majority opinion. The consensus protocol on which the blockchain system operates is no exception. As a distributed system, the blockchain system aims to maintain the validity of the system. Intuitively, the validity of the blockchain system has two meanings: firstly, there is no ambiguity, and secondly, it can process requests to update its status. The former corresponds to the safety requirements of distributed systems, while the latter to the requirements of liveness. The validity of distributed systems is mainly maintained by consensus protocols, considering the multiple nodes and network communication involved in such systems may be unstable, which has brought huge challenges to the design of consensus protocols.
The semi-synchronous network model and Byzantine fault tolerance
Researchers of distributed systems characterize these problems that may occur in nodes and network communications using node failure models and network models. The fail-stop failure in node failure models refers to the situation where the node itself stops running due to configuration errors or other reasons, thus unable to go on with the consensus protocol. This type of failure will not cause side effects on other parts of the distributed system except that the node itself stops running. However, for such distributed systems as the public blockchain, when designing a consensus protocol, we still need to consider the evildoing intended by nodes besides their failure. These incidents are all included in the Byzantine Failure model, which covers all unexpected situations that may occur on the node, for example, passive downtime failures and any deviation intended by the nodes from the consensus protocol. For a better explanation, downtime failures refer to nodes’ passive running halt, and the Byzantine failure to any arbitrary deviation of nodes from the consensus protocol.
Compared with the node failure model which can be roughly divided into the passive and active models, the modeling of network communication is more difficult. The network itself suffers problems of instability and communication delay. Moreover, since all network communication is ultimately completed by the node which may have a downtime failure or a Byzantine failure in itself, it is usually difficult to define whether such failure arises from the node or the network itself when a node does not receive another node’s network message. Although the network communication may be affected by many factors, the researchers found that the network model can be classified by the communication delay. For example, the node may fail to send data packages due to the fail-stop failure, and as a result, the corresponding communication delay is unknown and can be any value. According to the concept of communication delay, the network communication model can be divided into the following three categories:
- The synchronous network model: There is a fixed, known upper bound of delay $\Delta$ in network communication. Under this model, the maximum delay of network communication between two nodes in the network is $\Delta$. Even if there is a malicious node, the communication delay arising therefrom does not exceed $\Delta$.
- The asynchronous network model: There is an unknown delay in network communication, with the upper bound of the delay known, but the message can still be successfully delivered in the end. Under this model, the network communication delay between two nodes in the network can be any possible value, that is, a malicious node, if any, can arbitrarily extend the communication delay.
- The semi-synchronous network model: Assume that there is a Global Stabilization Time (GST), before which it is an asynchronous network model and after which, a synchronous network model. In other words, there is a fixed, known upper bound of delay in network communication $\Delta$. A malicious node can delay the GST arbitrarily, and there will be no notification when no GST occurs. Under this model, the delay in the delivery of the message at the time $T$ is $\Delta + max(T, GST)$.
The synchronous network model is the most ideal network environment. Every message sent through the network can be received within a predictable time, but this model cannot reflect the real network communication situation. As in a real network, network failures are inevitable from time to time, causing the failure in the assumption of the synchronous network model. Yet the asynchronous network model goes to the other extreme and cannot reflect the real network situation either. Moreover, according to the FLP (Fischer-Lynch-Paterson) theorem, under this model if there is one node fails, no consensus protocol will reach consensus in a limited time. In contrast, the semi-synchronous network model can better describe the real-world network communication situation: network communication is usually synchronous or may return to normal after a short time. Such an experience must be no stranger to everyone: the web page, which usually gets loaded quite fast, opens slowly every now and then, and you need to try before you know the network is back to normal since there is usually no notification. The peer-to-peer (P2P) network communication, which is widely used in blockchain projects, also makes it possible for a node to send and receive information from multiple network channels. It is unrealistic to keep blocking the network information transmission of a node for a long time. Therefore, all the discussion below is under the semi-synchronous network model.
The design and selection of consensus protocols for public chain networks that allow nodes to dynamically join and leave need to consider possible Byzantine failures. Therefore, the consensus protocol of a public chain network is designed to guarantee the security and liveness of the network under the semi-synchronous network model on the premise of possible Byzantine failure. Researchers of distributed systems point out that to ensure the security and liveness of the system, the consensus protocol itself needs to meet three requirements:
- Validity: The value reached by honest nodes must be the value proposed by one of them
- Agreement: All honest nodes must reach consensus on the same value
- Termination: The honest nodes must eventually reach consensus on a certain value
Validity and agreement can guarantee the security of the distributed system, that is, the honest nodes will never reach a consensus on a random value, and once the consensus is reached, all honest nodes agree on this value. Termination guarantees the liveness of distributed systems. A distributed system unable to reach consensus is useless.
The CAP theorem and Byzantine Generals Problem
In a semi-synchronous network, is it possible to design a Byzantine fault-tolerant consensus protocol that satisfies validity, agreement, and termination? How many Byzantine nodes can a system tolerance? The CAP theorem and Byzantine Generals Problem provide an answer for these two questions and have thus become the basic guidelines for the design of Byzantine fault-tolerant consensus protocols.
Lamport, Shostak, and Pease abstracted the design of the consensus mechanism in the distributed system in 1982 as the Byzantine Generals Problem, which refers to such a situation as described below: several generals each lead the army to fight in the war, and their troops are stationed in different places. The generals must formulate a unified action plan for the victory. However, since the camps are far away from each other, they can only communicate with each other through the communication soldiers, or, in other words, they cannot appear on the same occasion at the same time to reach a consensus. Unfortunately, among the generals, there is a traitor or two who intend to undermine the unified actions of the loyal generals by sending the wrong information, and the communication soldiers cannot send the message to the destination by themselves. It is assumed that each communication soldier can prove the information he has brought comes from a certain general, just as in the case of a real BFT consensus protocol, each node has its public and private keys to establish an encrypted communication channel for each other to ensure that its messages will not be tampered with in the network communication, and the message receiver can also verify the sender of the message based thereon. As already mentioned, any consensus agreement ultimately reached represents the consensus of the majority. In the process of generals communicating with each other for an offensive or retreat, a general also makes decisions based on the majority opinion from the information collected by himself.
According to the research of Lamport et al, if there are 1/3 or more traitors in the node, the generals cannot reach a unified decision. For example, in the following figure, assume there are 3 generals and only 1 traitor. In the figure on the left, suppose that General C is the traitor, and A and B are loyal. If A wants to launch an attack and informs B and C of such intention, yet the traitor C sends a message to B, suggesting what he has received from A is a retreat. In this case, B can’t decide as he doesn’t know who the traitor is, and the information received is insufficient for him to decide. If A is a traitor, he can send different messages to B and C. Then C faithfully reports to B the information he received. At this moment as B receives conflicting information, he cannot make any decisions. In both cases, even if B had received consistent information, it would be impossible for him to spot the traitor between A and C. Therefore, it is obvious that in both situations shown in the figure below, the honest General B cannot make a choice.
According to this conclusion, when there are $n$ generals with at most $f$ traitors (n≤3f), the generals cannot reach a consensus if $n \leq 3f$; and with $n > 3f$, a consensus can be reached. This conclusion also suggests that when the number of Byzantine failures $f$ exceeds 1/3 of the total number of nodes $n$ in the system $f \ge n/3$ , no consensus will be reached on any consensus protocol among all honest nodes. Only when $f < n/3$, such condition is likely to happen, without loss of generality, and for the subsequent discussion on the consensus protocol, $ n \ge 3f + 1$ by default.
The conclusion reached by Lamport et al. on the Byzantine Generals Problem draws a line between the possible and the impossible in the design of the Byzantine fault tolerance consensus protocol. Within the possible range, how will the consensus protocol be designed? Can both the security and liveness of distributed systems be fully guaranteed? Brewer provided the answer in his CAP theorem in 2000. It indicated that a distributed system requires the following three basic attributes, but any distributed system can only meet two of the three at the same time.
- Consistency: When any node responds to the request, it must either provide the latest status information or provide no status information
- Availability: Any node in the system must be able to continue reading and writing
- Partition Tolerance: The system can tolerate the loss of any number of messages between two nodes and still function normally
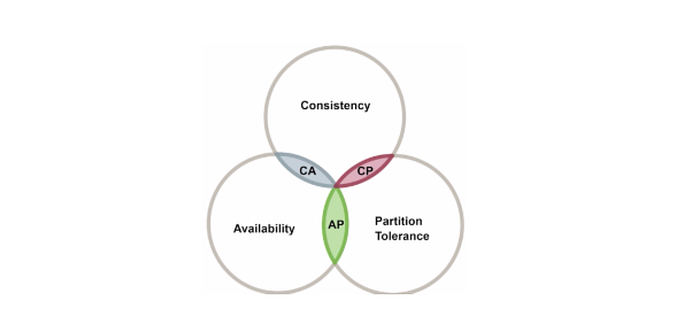
A distributed system aims to provide consistent services. Therefore, the consistency attribute requires that the two nodes in the system cannot provide conflicting status information or expired information, which can ensure the security of the distributed system. The availability attribute is to ensure that the system can continuously update its status and guarantee the availability of distributed systems. The partition tolerance attribute is related to the network communication delay, and, under the semi-synchronous network model, it can be the status before GST when the network is in an asynchronous status with an unknown delay in the network communication. In this condition, communicating nodes may not receive information from each other, and the network is thus considered to be in a partitioned status. Partition tolerance requires the distributed system to function normally even in network partitions.
The proof of the CAP theorem can be demonstrated with the following diagram. The curve represents the network partition, and each network has four nodes, distinguished by the numbers 1, 2, 3, and 4. The distributed system stores color information, and all the status information stored by all nodes is blue at first.
- Partition tolerance and availability mean the loss of consistency: When node 1 receives a new request in the leftmost image, the status changes to red, the status transition information of node 1 is passed to node 3, and node 3 also updates the status information to red. However, since node 3 and node 4 did not receive the corresponding information due to the network partition, the status information is still blue. At this moment, if the status information is queried through node 2, the blue returned by node 2 is not the latest status of the system, thus losing consistency.
- Partition tolerance and consistency mean the loss of availability: In the middle figure, the initial status information of all nodes is blue. When node 1 and node 3 update the status information to red, node 2 and node 4 maintain the outdated information as blue due to network partition. Also when querying status information through node 2, you need to first ask other nodes to make sure you’re in the latest status before returning status information as node 2 needs to follow consistency, but because of the network partition, node 2 cannot receive any information from node 1 or node 3. Then node 2 cannot determine whether it is in the latest status, so it chooses not to return any information, thus depriving the system of availability.
- Consistency and availability mean the loss of the partition tolerance: In the right-most figure, the system does not have a network partition at first, and both status updates and queries can go smoothly. However, once a network partition occurs, it degenerates into one of the previous two conditions. It is thus proved that any distributed system cannot have consistency, availability, and partition tolerance all at the same time.

The discovery of the CAP theorem seems to declare that the aforementioned goals of the consensus protocol is impossible. However, if you’re careful enough, you may find from the above that those are all extreme cases, such as network partitions that cause the failure of information transmission, which could be rare, especially in P2P network. In the second case, the system rarely returns the same information with node 2, and the general practice is to query other nodes and return the latest status as believed after a while, regardless of whether it has received the request information of other nodes. Therefore, although the CAP theorem points out that any distributed system cannot satisfy the three attributes at the same time, it is not a binary choice, as the designer of the consensus protocol can weigh up all the three attributes according to the needs of the distributed system. However, as the communication delay is always involved in the distributed system, one always needs to choose between availability and consistency while ensuring a certain degree of partition tolerance. Specifically, in the second case, it is about the value that node 2 returns: a probably outdated value or no value. Returning the possibly outdated value may violate consistency but guarantees availability; yet returning no value deprives the system of availability but guarantees its consistency. Tendermint consensus protocol to be introduced is consistent in this trade-off. In other words, it will lose availability in some cases.
The genius of Satoshi Nakamoto is that with constraints of the CAP theorem, he managed to reach a reliable Byzantine consensus in a distributed network by combining PoW mechanism, Satoshi Nakamoto consensus, and economic incentives with appropriate parameter configuration. Whether Bitcoin’s mechanism design solves the Byzantine Generals Problem has remained a dispute among academicians. Garay, Kiayias, and Leonardos analyzed the link between Bitcoin mechanism design and the Byzantine consensus in detail in their paper The Bitcoin Backbone Protocol: Analysis and Applications. In simple terms, the Satoshi Consensus is a probabilistic Byzantine fault-tolerant consensus protocol that depends on such conditions as the network communication environment and the proportion of malicious nodes’ hashrate. When the proportion of malicious nodes’ hashrate does not exceed 1/2 in a good network communication environment, the Satoshi Consensus can reliably solve the Byzantine consensus problem in a distributed environment. However, when the environment turns bad, even with the proportion within 1/2, the Satoshi Consensus may still fail to reach a reliable conclusion on the Byzantine consensus problem. It is worth noting that the quality of the network environment is relative to Bitcoin’s block interval. The 10-minute block generation interval of the Bitcoin can ensure that the system is in a good network communication environment in most cases, given the fact that the broadcast time of a block in the distributed network is usually just several seconds. In addition, economic incentives can motivate most nodes to actively comply with the agreement. It is thus considered that with the current Bitcoin network parameter configuration and mechanism design, the Bitcoin mechanism design has reliably solved the Byzantine Consensus problem in the current network environment.
Practical Byzantine Fault Tolerance, PBFT
It is not an easy task to design the Byzantine fault-tolerant consensus protocol in a semi-synchronous network. The first practically usable Byzantine fault-tolerant consensus protocol is the Practical Byzantine Fault Tolerance (PBFT) designed by Castro and Liskov in 1999, the first of its kind with polynomial complexity. For a distributed system with $n$ nodes, the communication complexity is $O(n²)$. Castro and Liskov showed in the paper that by transforming centralized file system into a distributed one using the PBFT protocol, the overwall performance was only slowed down by 3%. In this section we will briefly introduce the PBFT protocol, paving the way for further detailed explanations of the Tendermint protocol and the improvements of the Tendermint protocol.
The PBFT protocol that includes $n=3f+1$ nodes can tolerate up to $f$ Byzantine nodes. In the original paper of PBFT, full connection is required among all the $n$ nodes, that is, any two of the n nodes must be connected. All the nodes of the network jointly maintain the system status through network communication. In the Bitcoin network, a node can participate in or exit the consensus process through hashrate mining at any time, which is managed by the administrator, and the PFBT protocol needs to determine all the participating nodes before the protocol starts. All nodes in the PBFT protocol are divided into two categories, master nodes, and slave nodes. There is only one master node at any time, and all nodes take turns to be the master node. All nodes run in a rotation process called View, in each of which the master node will be reelected. The master node selection algorithm in PBFT is very simple: all nodes become the master node in turn by the index number. In each view, all nodes try to reach a consensus on the system status. It is worth mentioning that in the PBFT protocol, each node has its own digital signature key pair. All sent messages (including request messages from the client) need to be signed to ensure the integrity of the message in the network and the traceability of the message itself. (You can determine who sent a message based on the digital signature).
The following figure shows the basic flow of the PBFT consensus protocol. Assume that the current view’s master node is node 0. Client C initiates a request to the master node 0. After the master node receives the request, it broadcasts the request to all slave nodes that process the request of client C and return the result to the client. After the client receives f+1 identical results from different nodes (based on the signature value), the result can be taken as the final result of the entire operation. Since the system can have at most f Byzantine nodes, at least one of the f+1 results received by the client comes from an honest node, and the security of the consensus protocol guarantees that all honest nodes will reach consensus on the same status. So, the feedback from 1 honest node is enough to confirm that the corresponding request has been processed by the system.
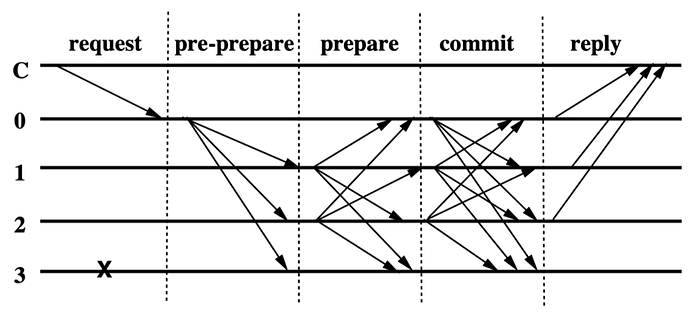
For the status synchronization of all honest nodes, the PBFT protocol has two constraints on each node: on one hand, all nodes must start from the same status, and on the other, the status transition of all nodes must be definite, that is, given the same status and request, the results after the operation must be the same. Under these two constraints, as long as the entire system agrees on the processing order of all transactions, the status of all honest nodes will be consistent. This is also the main purpose of the PBFT protocol: to reach a consensus on the order of transactions between all nodes, thereby ensuring the security of the entire distributed system. In terms of availability, the PBFT consensus protocol relies on a timeout mechanism to find anomalies in the consensus process and start the View Change protocol in time to try to reach a consensus again.
The figure above shows a simplified workflow of the PBFT protocol. Where C is the client, 0, 1, 2, and 3 represent 4 nodes respectively. Specifically, 0 is the master node of the current view, 1, 2, 3 are slave nodes, and node 3 is faulty. Under normal circumstances, the PBFT consensus protocol reaches consensus on the order of transactions between nodes through a three-phase protocol. These three phases are respectively: Pre-Prepare, Prepare, and Commit:
- The master node of the pre-preparation node is responsible for assigning the sequence number to the received client request, and broadcasting the
<PRE-PREPARE, v, n, d, sig>message to the slave node. The message contains the hash value of the client requestd, the sequence number of the current viewv, the sequence numbernassigned by the master node to the request, and the signature information of the master nodesig. The scheme design of the PBFT protocol separates the request transmission from the request sequencing process, and the request transmission is not to be discussed here. The slave node that receives the message accepts the message after confirming the message is legitimate and enter preparation phase. The message in this step checks the basic signature, hash value, current view, and, most importantly, whether the master node has given the same sequence number to other request from the client in the current view. - In preparation, the slave node broadcasts the message
<PREPARE, v, n, d, sig>to all nodes (including itself), indicating that it assigns the sequence numbernto the client request with the hash valuedunder the current viewv, with its signaturesigas proof. The node receiving the message will check the correctness of the signature, the matching of the view sequence number, etc., and accept the legitimate message. When thePRE-PREPAREmessage about a client request (from the main node) received by a node matches with thePREPAREfrom2fslave nodes, the system has agreed on the sequence number requested by the client in the current view. This means that2f+1nodes in the current view agree with the request sequence number. Since it contains information from at mostfmalicious nodes, there are a total off+1honest nodes that have agreed with the allocation of the request sequence number. With f malicious nodes, there are a total of2f+1honest nodes, sof+1represents the majority of the honest nodes, which is the consensus of the majority mentioned before. - After the node (including the master node and the slave node) receives a
PRE-PREPAREmessage requested by the client and2fPREPAREmessages, the message<COMMIT, v, n, d, sig>is broadcast across the network and enters the submission phase. This message is used to indicate that the node has observed that the whole network has reached a consensus on the sequence number allocation of the request message from the client. When the node receives2f+1COMMITmessages, there are at leastf+1honest nodes, that is, most of the honest nodes have observed that the entire network has reached consensus on the arrangement of sequence numbers of the request message from the client. The node can process the client request and return the execution result to the client at this moment.
Roughly speaking, in the pre-preparation phase, the master node assigns a sequence number to all new client requests. During preparation, all nodes reach consensus on the client request sequence number in this view, while in submission the consistency of the request sequence number of the client in different views is to be guaranteed. In addition, the design of the PBFT protocol itself does not require the request message to be submitted by the assigned sequence number, but out of order. That can improve the efficiency of the implementation of the consensus protocol. Yet, the messages are still processed by the sequence number assigned by the consensus protocol for the consistency of the distributed system.
In the three-phase protocol execution of the PBFT protocol, in addition to maintaining the status information of the distributed system, the node itself also needs to log all kinds of consensus information it receives. The gradual accumulation of logs will consume considerable system resources. Therefore, the PBFT protocol additionally defines checkpoints to help the node deal with garbage collection. You can set a checkpoint every 100 or 1000 sequence numbers according to the request sequence number. After the client request at the checkpoint is executed, the node broadcasts <CHEKPOINT, n, d, sig>messages throughout the network, indicating that after the node executes the client request with sequence number n, the hash value of the system status is d, and it is vouched by its own signature sig. After 2f+1 matching CHECKPOINT messages (one of which can come from the node itself) are received, most of the honest nodes in the entire network have reached a consensus on the system status after the execution of the client request with the sequence numbern, and then you can clear all relevant log records of client requests with the sequence number less than n. The node needs to save these2f+1 CHECKPOINTmessages as proof of the legitimate status at this moment, and the corresponding checkpoint is called a stable checkpoint.
The three-phase protocol of the PBFT protocol can ensure the consistency of the processing order of the client request, and the checkpoint mechanism is set to help nodes perform garbage collection and further ensures the status consistency of the distributed system, both of which can guarantee the security of the distributed system aforementioned. How is the availability of the distributed system guaranteed? In the semi-synchronous network model, a timeout mechanism is usually introduced, which is related to delays in the network environment. It is assumed that the network delay has a known upper bound after GST. In such condition, an initial value is usually set according to the network condition of the system deployed. In case of a timeout event, besides the corresponding processing flow triggered, additional mechanisms will be activated to readjust the waiting time. For example, an algorithm like TCP’s exponential back off can be adopted to adjust the waiting time after a timeout event.
To ensure the availability of the system in the PBFT protocol, a timeout mechanism is also introduced. In addition, due to the potential the Byzantine failure in the master node itself, the PBFT protocol also needs to ensure the security and availability of the system in this case. When the Byzantine failure occurs in the master node, for example, when the slave node does not receive the PRE-PREPARE message or the PRE-PREPARE message sent by the master node from the master node within the time window and is thus determined to be illegitimate, the slave node can broadcast <VIEW-CHANGE, v+1, n, C, P, sig> to the entire network, indicating that the node requests to switch to the new view with sequence number v+1. n indicates the request sequence number corresponding to the latest stable checkpoint local to the node, and C is to prove the stable checkpoint 2f+1 legitimate CHECKPOINT messages as aforementioned. After the latest stable checkpoint and before initiating the VIEWCHANGE message, the system may have reached a consensus on the sequence numbers of some request messages in the previous view. To ensure the consistency of these request sequence numbers to be switched in the view, the VIEWCHANGE message needs to carry this kind of the information to the new view, which is also the meaning of the P field in the message. P contains all the client request messages collected at the node with a request sequence number greater than n and the proof that a consensus has been reached on the sequence number in the node: the legitimate PRE-PREPARE message of the request and 2f matching PREPARE messages. When the master node in view v+1 collects 2f+1 VIEWCHANGE messages, it can broadcast the NEW-VIEW message and take the entire system into a new view. For the security of the system in combination with the three-phase protocol of the PBFT protocol, the construction rules of the NEW-VIEW information are designed in a quite complicated way. You can refer to the original paper of PBFT for more details.
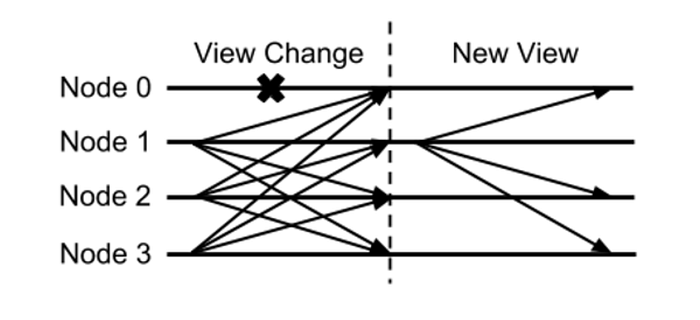
VIEWCHANGE contains a lot of information. For example, C contains 2f+1 signature information, P contains several signature sets, and each set has 2f+1 signature. At least 2f+1 nodes need to send a VIEWCHANGE message before prompting the system to enter the next new view, and that means, in addition to the complex logic of constructing the information of VIEWCHANGE and NEW-VIEW, the communication complexity of the view conversion protocol is $O(n^2)$. Such complexity also limits the PBFT protocol to support only a few nodes, and when there are 100 nodes, it is usually too complex to practically deploy PBFT. It is worth noting that in some materials the communication complexity of the PBFT protocol is inappropriately attributed to the full connection between n nodes. By changing the fully connected network topology to the P2P network topology based on distributed hash tables commonly used in blockchain projects, high communication complexity caused by full connection can be conveniently solved, yet still, it is difficult to improve the communication complexity during the view conversion process. In recent years, researchers have proposed to reduce the amount of communication in this step by adopting aggregate signature scheme. With this technology, 2f+1 signature information can be compressed into one, thereby reducing the communication volume during view change.
